Jinwoo Jang
Associate Professor & I-SENSE Fellow
NSF ENGINEERING RESEARCH CENTER FOR SMART STREETSACPES (NSF EEC-2133516)

The NSF Engineering Research Center for Smart Streetscapes (CS3) will advance livable, safe, and inclusive communities through real-time, hyper-local streetscape applications built on advancements in edge-cloud technology, wireless-optical engineering, visual analytics, computer security, and social science. CS3 will unite diverse research communities through a convergent research model that delivers innovations across five engineering and scientific areas. CS3 will advance fundamental knowledge in civil and urban systems engineering, electrical and network engineering, visual analytics and sensor fusion, computer privacy and security, and public trust and technology, catalyzing and coalescing the emerging discipline of smart cities.
In-VEHICLE SENSORS TO DETECT COGNITIVE CHANGE IN OLDER DRIVERS (NIH R01AG068472)
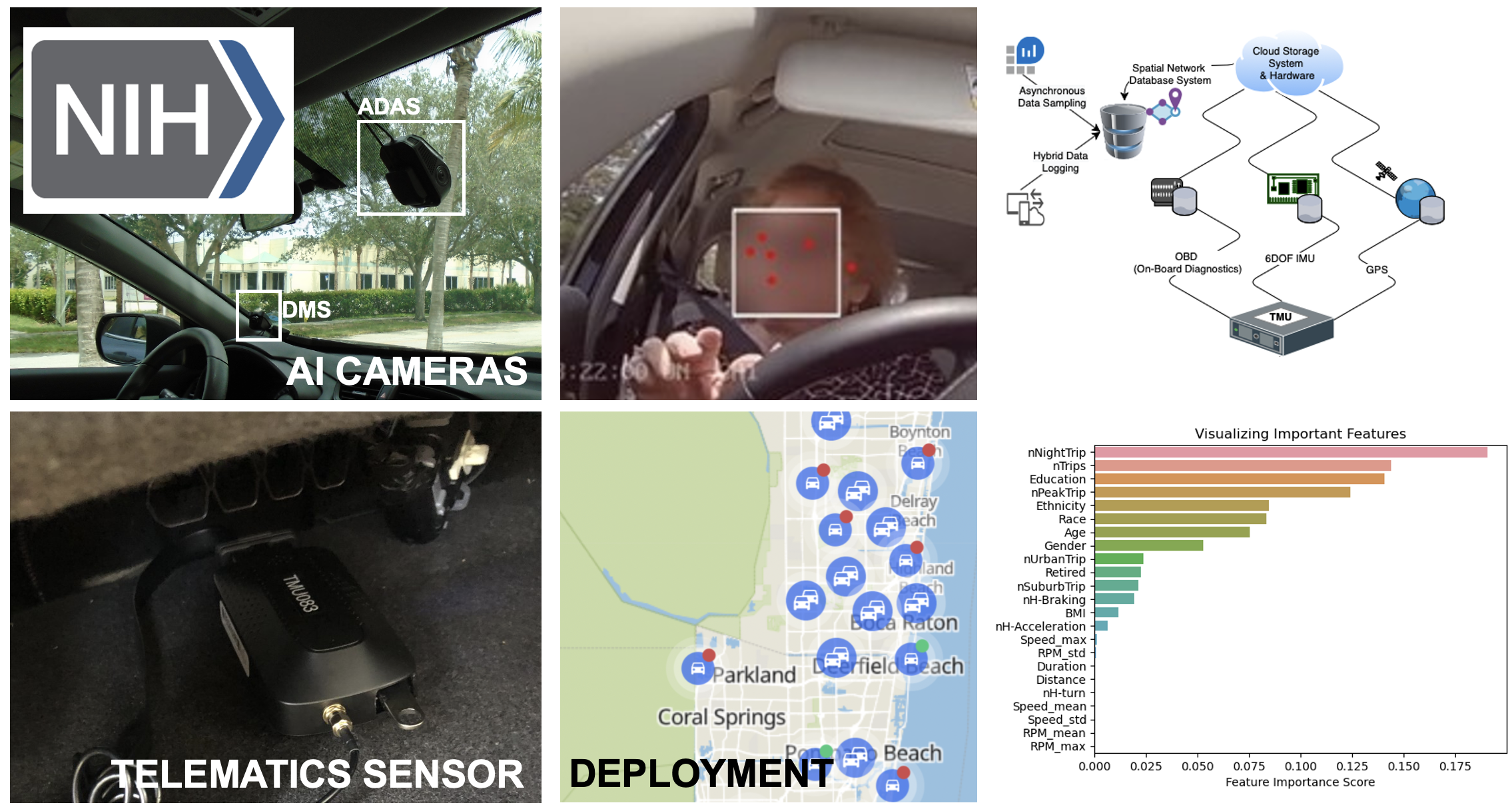
There are an estimated 4 to 8 million older drivers with mild cognitive impairment on the roads in the U.S., which poses a major concern for public safety. This project aims to develop an unobtrusive in-vehicle sensing system to provide the first step toward future widespread, low-cost, early warnings of change for the large number of older drivers in the U.S. Our in-vehicle sensing system includes unobtrusive cameras, on-board diagnostics (OBD), GPS and inertial measurement units (IMU) configured to track and record driver behavior in the passenger vehicles of these 750 older adult (≥ 65) drivers. The recorded changes in driver behavior are compared to results from a battery of cognitive tests (global cognition, executive function, memory, visuospatial, visual attention and language) with a demonstrated ability to detect early cognitive changes and to predict driver risk.
CONNECTED VEHICLE CYBERINFRASTRUCTURE (NSF OAC-1948066)
By 2030, nearly 146 million connected vehicles will be in operation in the U.S. Each vehicle will generate 25 gigabytes of data per hour; however, traditional data analytics systems are not capable of handling the high amount of data. The project aims to create a new data mining engine embedded at the vehicle level to collect and process the streams of data in a highly efficient and scalable way. Harnessing novel data science tools, this project will address important fundamental questions of how to efficiently decide what information to collect, what to filter, and what to process within a vehicle.
MACHINE-LEARNING-BASED PARAMETERIZATION
High-fidelity finite element (FE) models consist of the massive number of elements and each element has various physical parameters. Their high-dimensional parameter space pose extra challenges in understanding the relationships between model outputs and the status of a model. The objective of this research is to automatically find physically-meaningful and efficient groups of model parameters in an effort to reduce the dimension of parameter space into a more tangible format. We developed a machine-learning-based parameterization method, which can determine efficient groups of model parameters based on the sensitivities of model parameters. The developed method has applied to sensitivity-based and Bayesian model updating practices to make these inverse problems more affordable and tractable by efficiently reducing the parameter space of a sophisticated full-scale model.
HIGH FIDELITY SIMULATION OF TEMPERATURE EFFECT
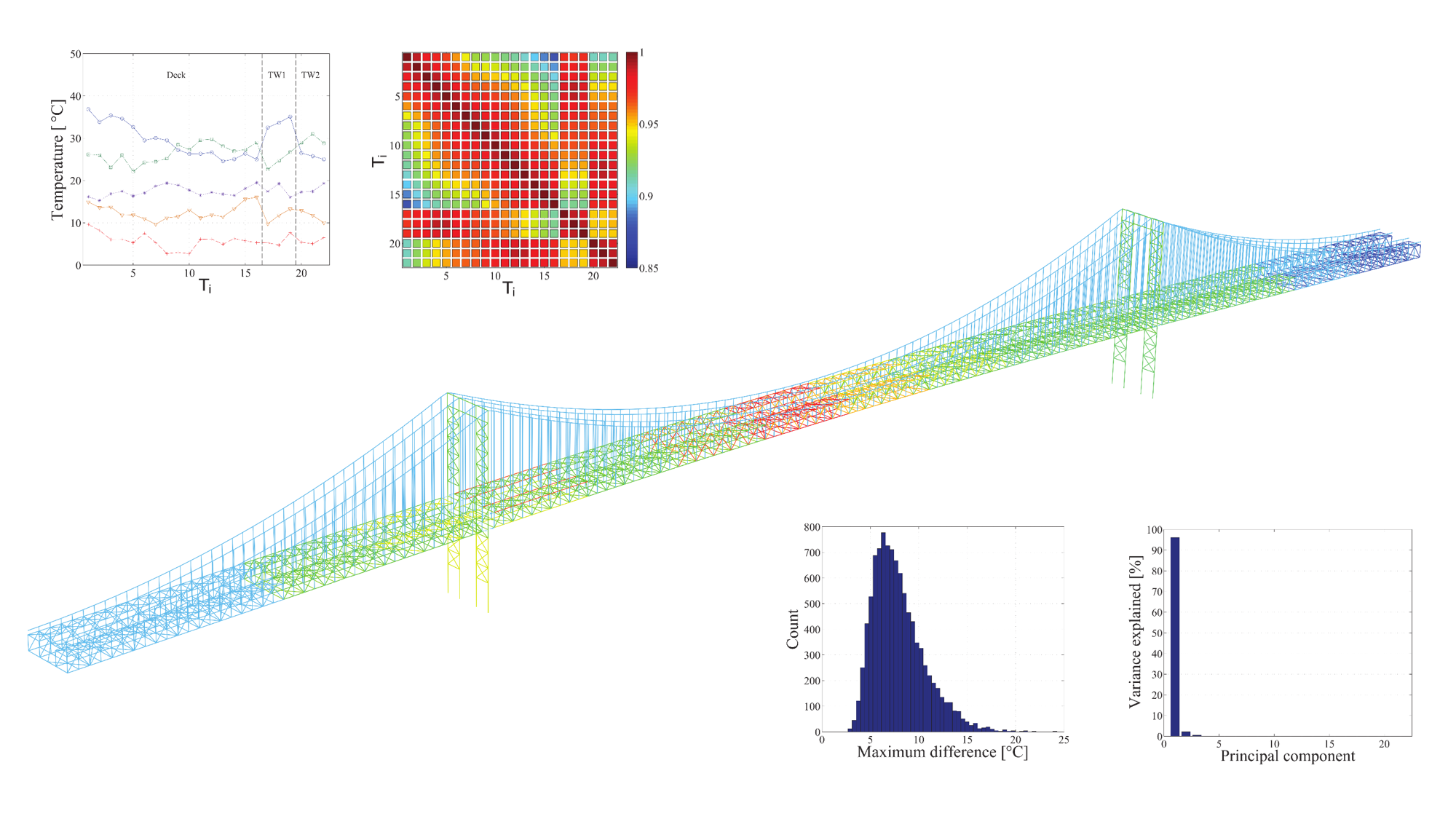
Civil structures are influenced by various operational and environmental conditions, such as traffic, wind, humidity, and most importantly, temperature. It is fundamentally important to distinguish temperature-related changes in structural responses from those related to structural damages since changes in model outputs caused by environmental effects can mask the effect of structural damage. This research work aims to investigate the effects of temperature distribution on natural frequencies with a full-scale finite element model. Temperature profiles of the model are hypothetically simulated and used to generate a large number of simulation datasets for training data-driven models. Developed data-driven models lead to an in-depth understanding of the effect of temperature distributions on modal properties of a structure.
IN-VEHICLE SENSING
We developed in-vehicle sensing devices to collect telematics data (a.k.a., connected vehicle data). The sensors comprise a microcomputer, an onboard diagnostic (OBD) scanner, an inertial measurement unit (IMU), and a GPS module. The sensors have the ability to collect high priority telematics data classified by the USDOT (e.g., trajectories, speed, heading, acceleration, engine status). These telematics data are critically important to understand driver behaviors, large-scale traffic flows, and public safety. These in-vehicle sensing devices have supported various funded research, educational outreach components, and undergraduate research experience.
BIG FLEET DATA ANALYTICS
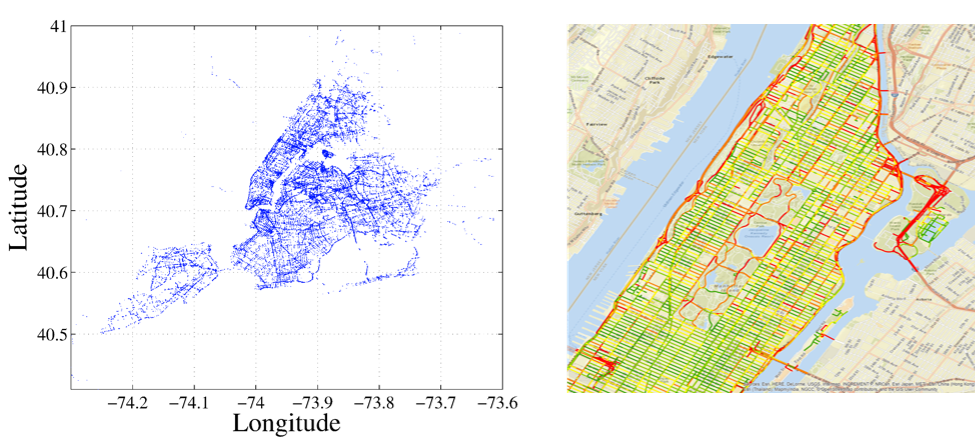
A massive amount of fleet trajectory data has become available to cities and communities due to the development of sensors and wireless technology. It gives great opportunities for cities and communities to utilize these newly-available data formats for their decision-making and planning processes. Online trajectory clustering algorithm, which necessitates fewer computation resources to process big trajectory data, was developed to pinpoint the hotspots of hard accelerations and braking. A map-matching algorithm, which can fuse another data source with GPS data to increase the computational efficiency and the accuracy of a result, was developed to clean up the measurement noise and to analyzes massive trajectory data on the basis of map data.
ROAD SURFACE MONITORING SYSTEM VIA CONNECTED VEHICLES

The objective of this research is to develop an innovative road surface monitoring system that can provide continuous city-wide information for the pavement distress management system. This proposed road surface monitoring system relies on various sensor data collected from connected vehicles and state-of-the-art data analytics at a backend server. The suggested monitoring system includes an embedded data logging algorithm to maximize the efficiency of data collection. It also utilizes a machine learning algorithm to classify collected sensor data into different types of pavement distress. More importantly, it leverages a data mining technique to integrate sensor data from the various connected vehicle based on their proximity and directionality to maximize the accuracy and reliability of outcomes of the suggested monitoring system.